socket backlog 过小导致丢连接
事情起因
2016年1月12日, 有人发现Nginx 与前端机之间有较多 Connection timeout 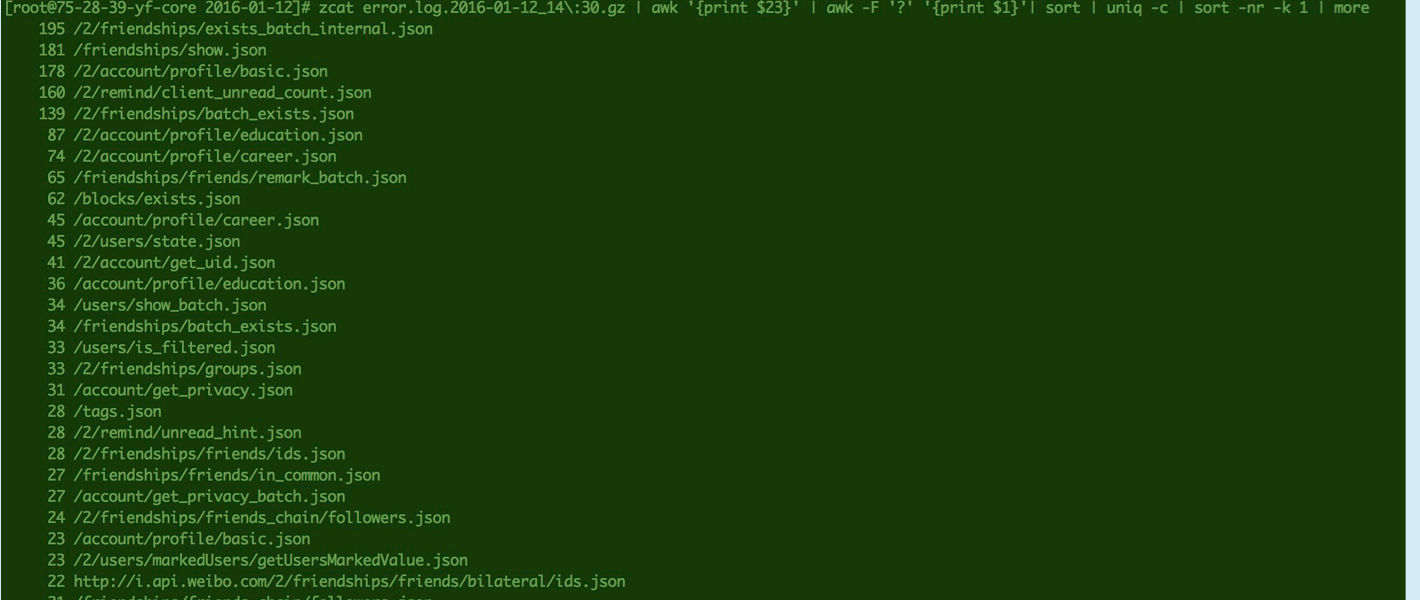
初步怀疑是用户前端机 QPS 很高,而socket listen() 的 backlog 设置过小(目前使用 cedrus 框架的服务都是 HTTP 短连接,每次 request 都需重新建立 socket 连接,然后关闭)。目前我们 centos7 系统 net.ipv4.tcp_syn_retries = 6(之前 centos6设置的好像是 3),当服务端 socket listen() 的 SYN 的队列满了,客户端发出 SYN 后,服务端直接 DROP 后续的 SYN 请求,客户端一直收不到服务端的任何回复(ACK 或 RST),发出的 SYN 像进入黑洞,会重试直至6次或超过 Nginx 配置的超时(30s),从而爆出 connection timedout。
周三紧急上线, 将 Tomcat acceptCount 由 700 增大至 1024。统计后有效果。
与 backlog 有关的参数设置
-
Tomcat backlog
server.xml 中 acceptCount
-
somaxconn
Limit of socket listen() backlog, known in userspace as somaxconn.
实际 listen 中的 backlog 为 min(acceptCount, somaxconn)
此处 backlog 指定 server 端接收客户端 SYN 尚未 ACK 的 queue 的大小
SYSCALL_DEFINE2(listen, int, fd, int, backlog)
{
struct socket *sock;
int err, fput_needed;
int somaxconn;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn;
if ((unsigned int)backlog > somaxconn)
backlog = somaxconn;
err = security_socket_listen(sock, backlog);
if (!err)
err = sock->ops->listen(sock, backlog);
fput_light(sock->file, fput_needed);
}
return err;
}
-
tcp_max_syn_backlog
Maximal number of remembered connection requests, which have not received an acknowledgment from connecting client. The minimal value is 128 for low memory machines, and it will increase in proportion to the memory of machine. If server suffers from overload, try increasing this number.
tcp_max_syn_backlog 指定待传递给 accept() 的 queue 的大小,即 server 端已对 SYN 发送了 ACK,但是还没有接收到客户端的 ACK
对应源码有
int sk_receive_skb(struct sock *sk, struct sk_buff *skb, const int nested)
{
int rc = NET_RX_SUCCESS;
if (sk_filter(sk, skb))
goto discard_and_relse;
skb->dev = NULL;
if (sk_rcvqueues_full(sk, sk->sk_rcvbuf)) {
atomic_inc(&sk->sk_drops);
goto discard_and_relse;
}
if (nested)
bh_lock_sock_nested(sk);
else
bh_lock_sock(sk);
if (!sock_owned_by_user(sk)) {
/*
* trylock + unlock semantics:
*/
mutex_acquire(&sk->sk_lock.dep_map, 0, 1, _RET_IP_);
rc = sk_backlog_rcv(sk, skb);
mutex_release(&sk->sk_lock.dep_map, 1, _RET_IP_);
} else if (sk_add_backlog(sk, skb, sk->sk_rcvbuf)) {
bh_unlock_sock(sk);
atomic_inc(&sk->sk_drops);
goto discard_and_relse;
}
bh_unlock_sock(sk);
out:
sock_put(sk);
return rc;
discard_and_relse:
kfree_skb(skb);
goto out;
}
static inline bool sk_rcvqueues_full(const struct sock *sk, unsigned int limit)
{
unsigned int qsize = sk->sk_backlog.len + atomic_read(&sk->sk_rmem_alloc);
return qsize > limit;
}
-
netdev_max_backlog
Maximum number of packets taken from all interfaces in one polling cycle (NAPI poll). In one polling cycle interfaces which are registered to polling are probed in a round-robin manner.
NAPI (New API ) is an interface to use interrupt mitigation techniques for networking devices in the Linux kernel. 采用轮询(poll)方式,等到接收的 packets 积累到一定数量后再一次性全部读取,以前的机制是每次有 packet 到来触发中断让 CPU 读取。netdev_max_backlog 是网卡的每个 napi sk_buff 接收队列的的长度
关于多队列网卡的介绍,可参考http://blog.csdn.net/turkeyzhou/article/details/7528182
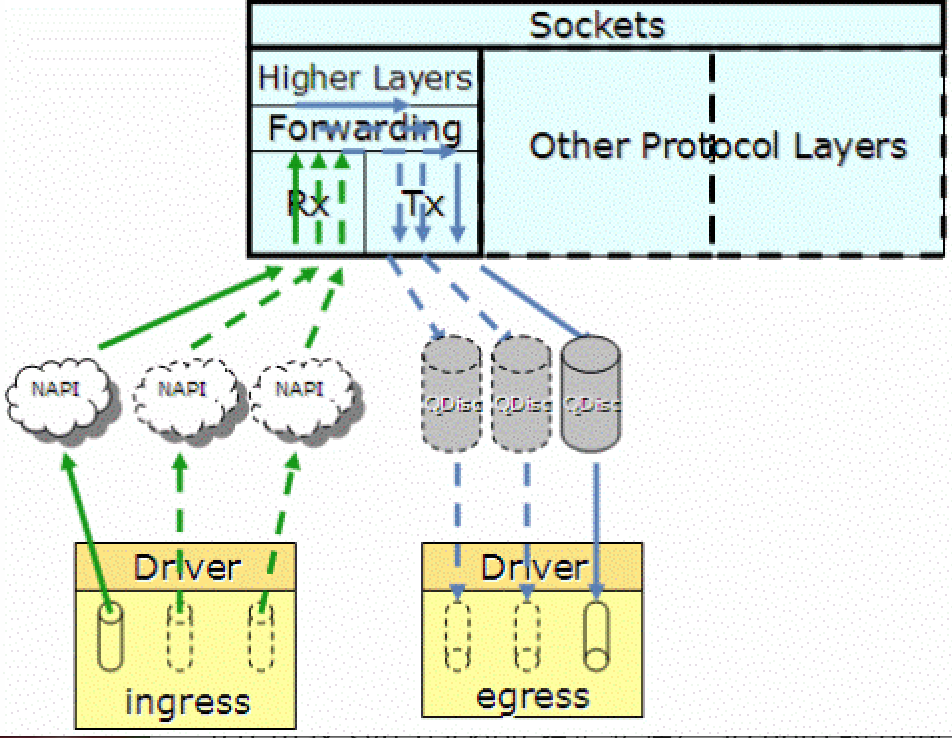
对应源码有
static inline void gro_cells_receive(struct gro_cells *gcells, struct sk_buff *skb)
{
struct gro_cell *cell;
struct net_device *dev = skb->dev;
if (!gcells->cells || skb_cloned(skb) || !(dev->features & NETIF_F_GRO)) {
netif_rx(skb);
return;
}
cell = this_cpu_ptr(gcells->cells);
if (skb_queue_len(&cell->napi_skbs) > netdev_max_backlog) {
atomic_long_inc(&dev->rx_dropped);
kfree_skb(skb);
return;
}
__skb_queue_tail(&cell->napi_skbs, skb);
if (skb_queue_len(&cell->napi_skbs) == 1)
napi_schedule(&cell->napi);
}
/* enqueue_to_backlog is called to queue an skb to a per CPU backlog
* queue (may be a remote CPU queue).
*/
static int enqueue_to_backlog(struct sk_buff *skb, int cpu,
unsigned int *qtail)
{
struct softnet_data *sd;
unsigned long flags;
unsigned int qlen;
sd = &per_cpu(softnet_data, cpu);
local_irq_save(flags);
rps_lock(sd);
if (!netif_running(skb->dev))
goto drop;
qlen = skb_queue_len(&sd->input_pkt_queue);
if (qlen <= netdev_max_backlog && !skb_flow_limit(skb, qlen)) {
if (qlen) {
enqueue:
__skb_queue_tail(&sd->input_pkt_queue, skb);
input_queue_tail_incr_save(sd, qtail);
rps_unlock(sd);
local_irq_restore(flags);
return NET_RX_SUCCESS;
}
/* Schedule NAPI for backlog device
* We can use non atomic operation since we own the queue lock
*/
if (!__test_and_set_bit(NAPI_STATE_SCHED, &sd->backlog.state)) {
if (!rps_ipi_queued(sd))
____napi_schedule(sd, &sd->backlog);
}
goto enqueue;
}
drop:
sd->dropped++;
rps_unlock(sd);
local_irq_restore(flags);
atomic_long_inc(&skb->dev->rx_dropped);
kfree_skb(skb);
return NET_RX_DROP;
}
backlog 建议值
参考《性能之巅》以及前端机现状,具体还需要线上灰度验证,也可以用 systemTap 看一下。对于 10G 网卡《性能之巅》建议 netdev_max_backlog = 10000,使用的前端机是 1G 网卡。
| 目前值 | 建议值 | |
|---|---|---|
| somaxconn | 1024 | 4096 |
| tcp_max_syn_backlog | 8192 | 8192 |
| netdev_max_backlog | 1000 | 5000 |
| Tomcat acceptCount | 1024 | 2048 |
附
这篇http://www.blogjava.net/yongboy/archive/2015/01/30/422592.html 概括了Linux系统网络堆栈的常规扩展优化措施
| RSS (Receive Side Scaling) | RPS (Receive Packet Steering) | RFS (Receive Flow Steering) | Accelerated RFS(Accelerated Receive Flow Steering) | XPS (Transmit Packet Steering) | |
|---|---|---|---|---|---|
| 解决问题 | 网卡和驱动支持 | 软件方式实现RSS | 数据包产生的中断和应用处理在同一个CPU上 | 基于RFS硬件加速的负载平衡机制 | 智能选择网卡多队列的队列快速发包 |
| 内核支持 | 2.6.36开始引入,需要硬件支持 | 2.6.35 | 2.6.35 | 2.6.35 | 2.6.38 |
| 建议 | 网卡队列数和物理核数一致 | 至此多队列的网卡若RSS已经配置了,则不需要RPS了 | 需要rps_sock_flow_entries和rps_flow_cnt属性 | 需要网卡设备和驱动都支持加速。并且要求ntuple过滤已经通过ethtool启用 | 单传输队列的网卡无效,若队列比CPU少,共享指定队列的CPU最好是与处理传输硬中断的CPU共享缓存的CPU |
| fastsocket | 网卡特性 | 改进版RPS,性能提升 | 源码包含,文档没有涉及 | 文档没有涉及 | 要求发送队列数要大于CPU核数 |
| 传送方向 | 网卡接收 | 内核接收 | CPU接收处理 | 加速并接收 | 网卡发送数据 |
顺便查看了前端机的配置,应该是采用了网卡和驱动支持的 RSS 方式。接受和发送队列数为 8, 与超线程 24 相差较大,通过 top 也可以看出 si 软中断集中在 8 个 超线程的核上 ,都不高,说明 si 并非瓶颈,具体到 cache miss 如何,尚不可知。优化收益应该比较小
关于周四发现的阿里云 cpu0 si 特别高的现象,可以参考http://www.leozwang.com/2015/05/05/多队列网卡中断均衡问题/ 看是否可设置。