CNN paper note
Data Augmentation
- RandomResizedCrop, TenCrop, FiveCrop
- RandomHorizontalFlip
- ColorJitter
- PCA Jittering
- Supervised Data Augmentation, 训练一个粗模型,选取 high prob. location 作 Crop
- 海康威视 Label Shuffling
YOLO
将图像分块(如 7 * 7),对每一块预测 object confidence & boxes, and class prob., then combined to do NMS

输出 7 x 7 x 30 (30 = B x 5 + C, C = Pascal 20 个分类,B = 每个 grid 2 个 bouding box, 5 = object confidence + [x, y, w, h])
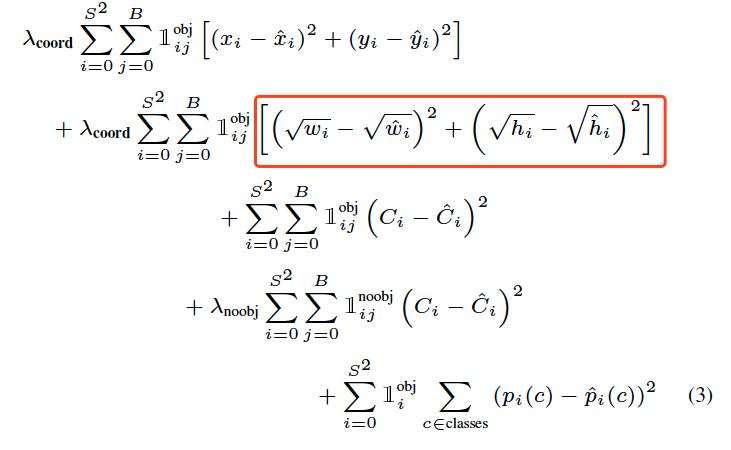
计算 w, h loss 使用 square root of bouding box width and height 可做到 small deviations in larger boxes matter less than in small boxes
图片截自 解读YOLO目标检测方法
缺点:
- 1 个 grid 只能识别 1 个 class 并输出 2 个 box,如果 1 个 grid 中有 2 个及以上类别的物体则全部正确分类(可以将图像分块成更小的 grid)
- 1 个 grid 中有 2 个相同 class 的物体。训练时 gound truth 和 bounding box 是一一对应的,两个尺寸、位置相近的 ground truth 对应同一个 bounding box 来训练
YOLOv2 学习 Faster RCNN 使用多个 anchor YOLOv3: class prediction: using independent logistic classifiers rather than softmax; anchors: 9 clusters and 3 scales
SSD
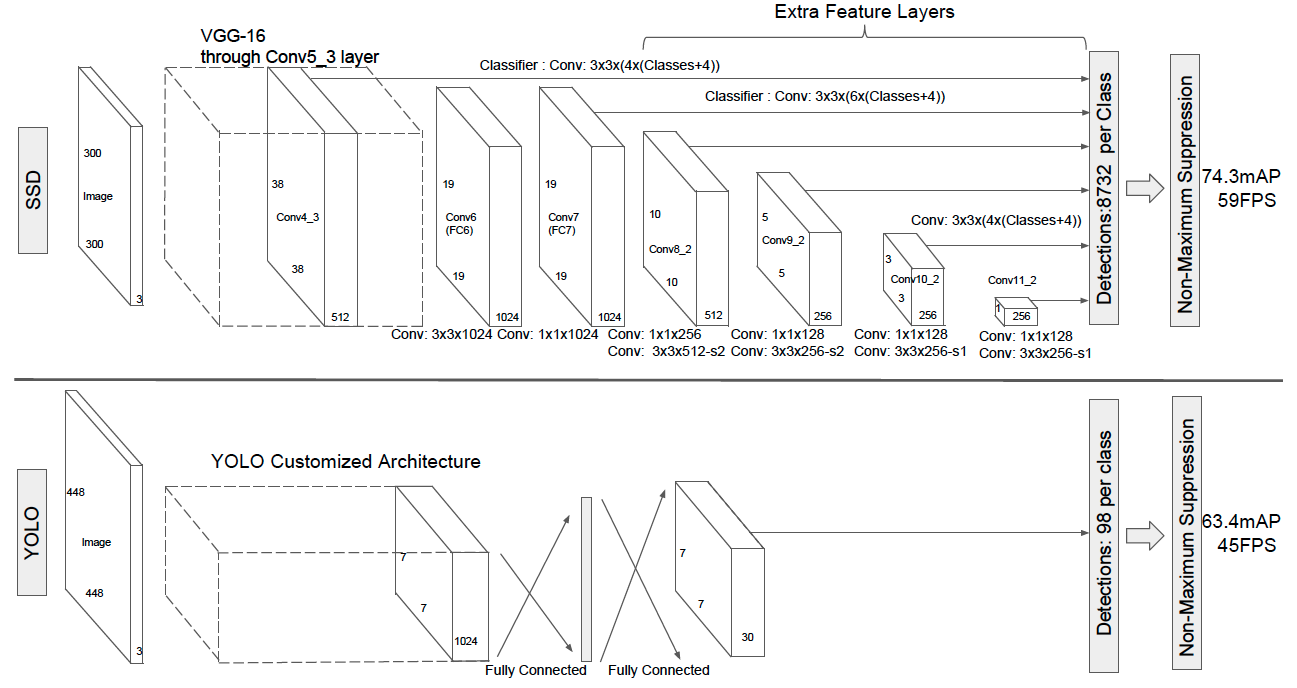
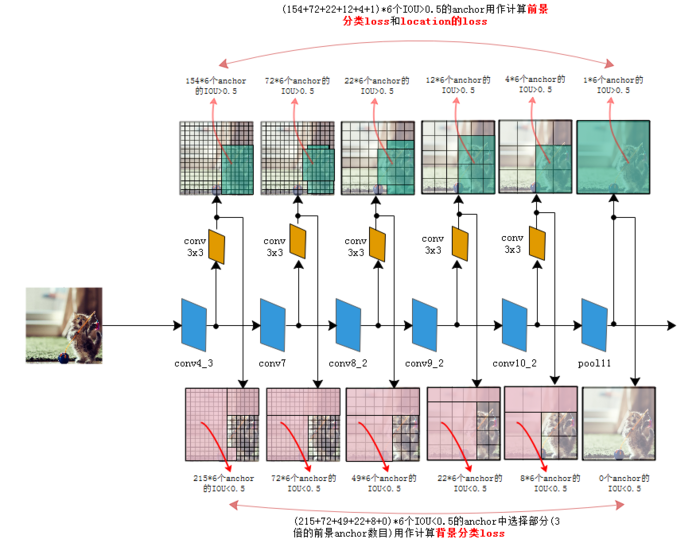
参考文章 解读SSD目标检测方法
论文中 default box = Faster R-CNN anchor
沿用 YOLO 中直接回归 bbox 和 分类概率,feature pyramids 寻找较大 IoU 的 anchors 进行训练
loss: weighted sum between localization loss(Smooth L1) and confidence loss (Softmax)
针对 SSD 对小物体检测比较差(小尺寸的目标多用较低层级的 anchor 来训练, 无法用到后层网络提取更抽象特征提高精确度),Zoom out 训练数据 (random crop 相当于 Zoom in 小),将图片放大到原始图片的 16 倍(使用均值填充),然后再 random crop,这样获取放大了 16 倍后的小物体
Using feature maps from the lower layers can improve semantic segmentation quality because the lower layers capture more fine details of the inputs object; Adding global context pooled from a feature map can help smooth the segmentation results.
Hard negative mining: negatives(select highest confidence loss, 更难分类为负样本的数据) : positives = 3 : 1
Focal Loss
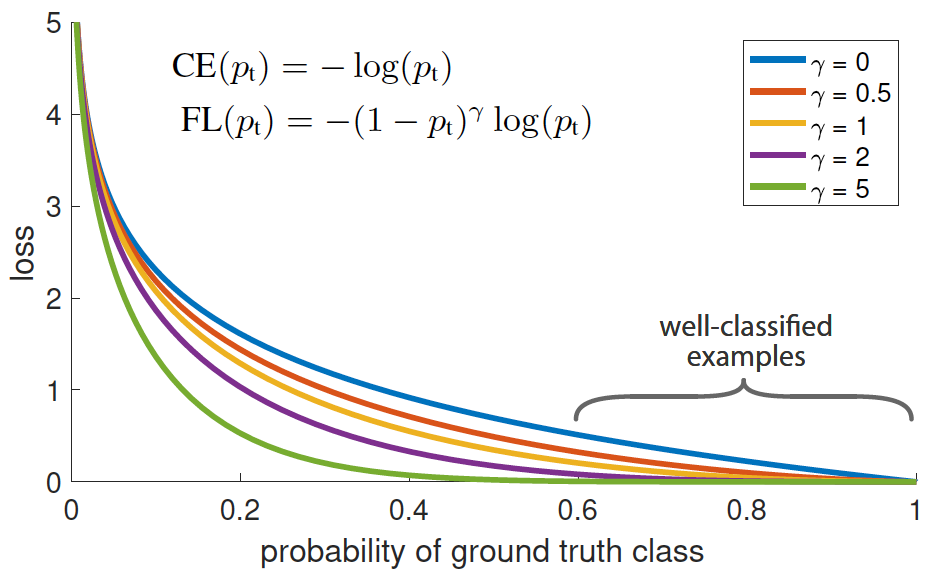
参考文章 Focal Loss for Dense Object Detection解读
Why is two-stage better than one stage?
-
SelectiveSearch, EdgeBoxes, RPN etc. narrows down number of proposals to a small number(1 ~ 2k), filtering out most backgroud samples(many easy negatives)
-
in second classfication stage, sampling heuristics(fixed negatives : positives = 3 : 1, or OHEM) mantain a balance
与 OHEM 比较:通过对 loss 排序,选出 loss 最大的 examples 来进行训练,这样就能保证训练的区域都是 hard example。缺陷是完全忽略了easy examples ,造成 easy positive examples 无法进一步提升训练的精度。
Faster R-CNN
Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network
PixelShuffle in PyTorch
create much sharper and higher contrast images
Non-local Neural Networks
by computing interactions between any two positions
DeepLab
- atrous conv (dilated Conv)
- atrous spatial pyramid pooling
- fully connected pairwise CRF (to capture fine edge details while also catering for long range dependencies)
Bilinear interpolation is sufficient because the class score maps (corresponding to log-probabilities) are quite smooth.