JVM tune
JVM 调优总结
java -XX:+UseConcMarkSweepGC -server -Xms10g -Xmx10g -Xmn5400m -XX:+PrintFlagsFinal -version > gc_params.txt
打印 `GC` 参数
Elephant in the room
如果不了解分代 GC 和 card table, 可参考http:/blogs.msdn.com/b/abhinaba/archive/2009/03/02/back-to-basics-generational-garbage-collection.aspx
调优前部署环境
用户关系前端物理机主要类型是 24 超线程 CPU + 16G Mem, Java 1.7.0_75版本
每台机器部署 2 个 Tomcat 实例,服务端口分别为 8080 和 9080, 每个实例堆为 5G,主要参数如下:
-Xms5000m -Xmx5000m -Xmn1500m -server -XX:PermSize=128m -XX:MaxPermSize=128m -XX:SurvivorRatio=10 -XX:MaxTenuringThreshold=12 -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75
YGC 的平均停顿时间在 80 ~ 90ms,CMS GC 停顿时间在 500ms 以上。
JVM 堆内存调优
JVM 调优的目的:保证或提高 SLA && 提高 QPS
直观的想法是在单机双实例的基础上再增加实例,形成 3 实例或 4 实例。在 tcpcopy 下,测试 3 实例,平均响应时间反而恶化,且很容易出现碎片化太多触发 Full GC。
分析下来,由于多个实例是多个进程,并不共享数据,多 1 份实例,就多一份 1 份 liveset(前端机 live set 有 700+ MB) + 预防过早碎片化而保留的内存 ——至少 1G 内存的使用,也就增加了内存短板效应。
一般的建议是内存 < 3G, 不使用 CMS GC。如果使用 ParallelOldGC,Old GC 的停顿跟 Old 区大小成比例,约在 0.5 ~1 s/GB,平台接口基本约定在 400ms 超时,不满足要求,而 CMS GC 的 Old GC stop-the-world 阶段并不与 Old 区大小相关,所以决定在大堆上尝试 CMS GC。
每台机器由原先部署 2 个实例,改为部署 1 个实例,堆为 10G,主要参数如下:
-Xms10g -Xmx10g -Xmn5g -server -XX:PermSize=128m -XX:MaxPermSize=128m -XX:+UseConcMarkSweepGC
灰度的结果
在去年 11 月 11 日 晚高峰窗口期(20:00 - 24:00)灰度的 SLA 结果如下:
注:28-29 指不同机器,QPS的单位 1 是指部署双实例时 1 个实例的 QPS,1 + 1 代表双实例部署, 2 代表单实例部署且 2 倍的 QPS, 数据项是 响应平均时间 / 最大时间
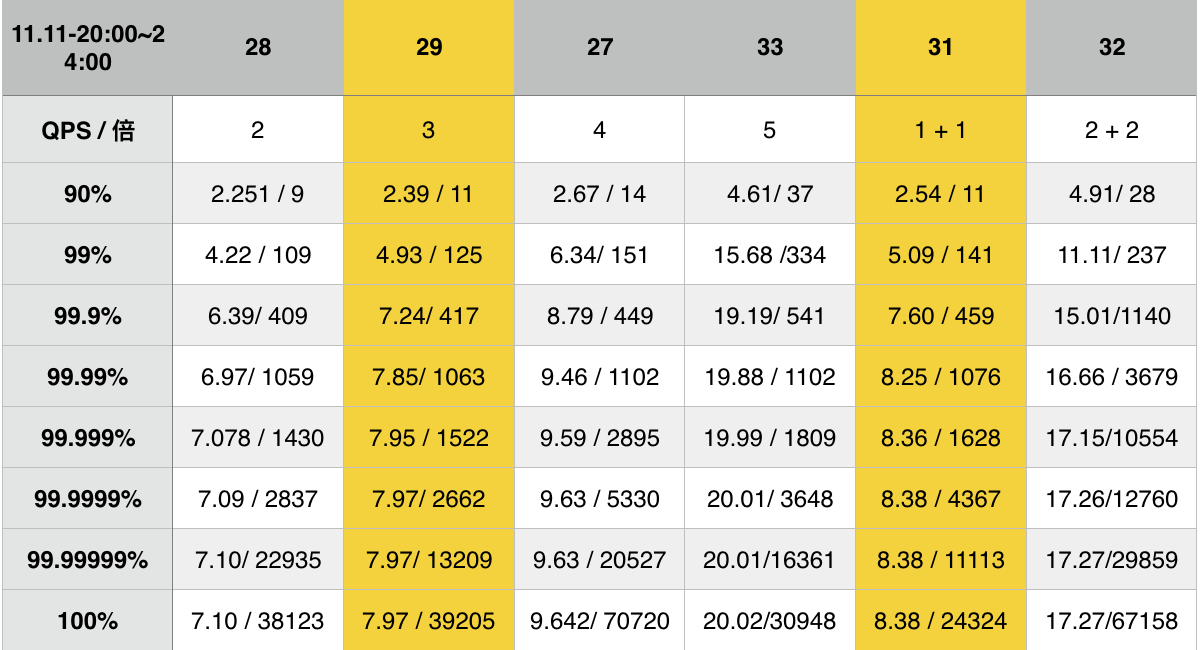
CPU 利用率如下:
注:由下到上,绿色线是机器28,黄色线是机器31,红色线是机器29,蓝色线是机器27,咖啡色线是32,粉红色线是机器33
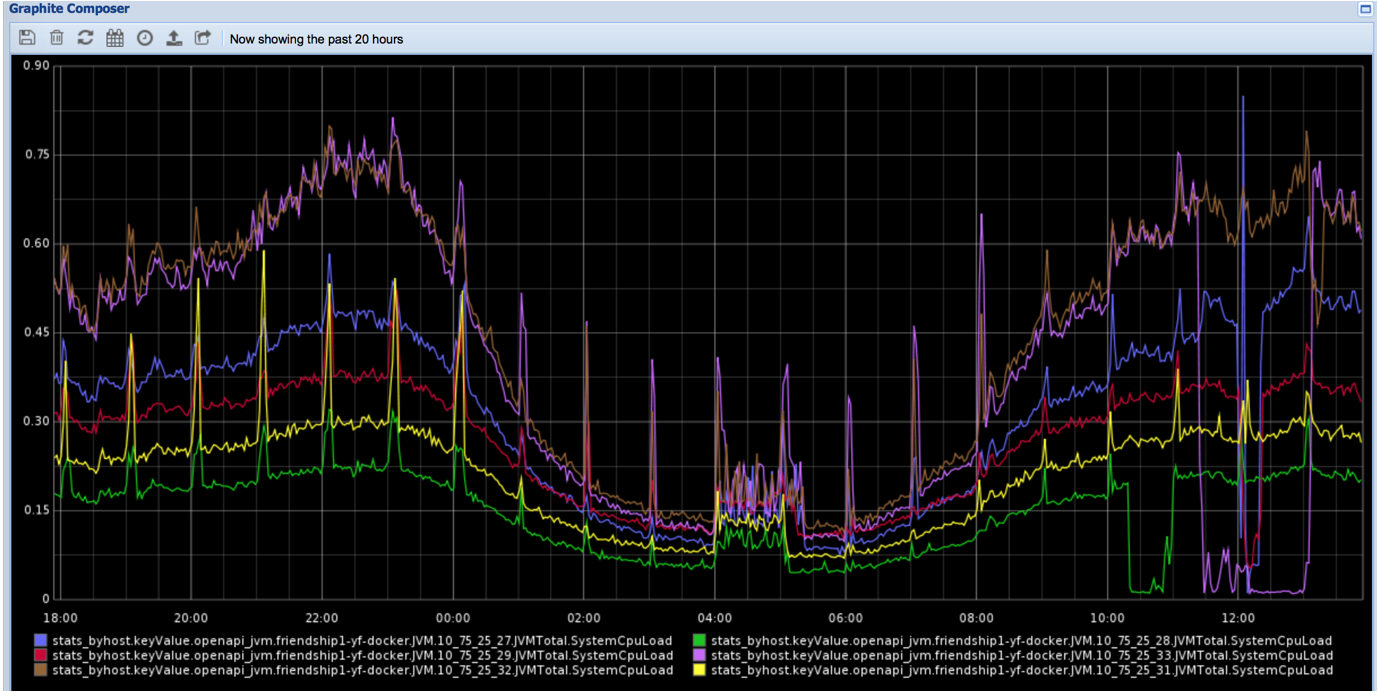
从表中对比可以得出,双实例合并成大堆单实例,SLA 有着较好的提升 ,同时从图中看 CPU 利用率有着显著的下降。
原因有:
-
调优前 1 个实例 Eden 区 1.35G, 调优后 5G,总共增大了 5 /(1.35 * 2)= 1.85 。在晚高峰窗口期 YGC 间隔时间由 1~2s 提升到 3s 左右,从而减少 GC 的 CPU 使用率。
-
合并成1个实例后,减少了 1 份 JVM 线程和应用线程,从而减小 CPU 调度的繁忙程度
所以我们调优的方向是合并小堆双实例为大堆单实例,然后进行细粒度调优。
细粒度 JVM 调优准备
测量方法
-
挑选机器
- 先扫描一遍池子中的机器 CPU, Mem ,OS 情况。用户关系前端机 CPU 有 8 、12核,开启和没开启超线程的,Mem 有 8G, 12G, 14G, 16G, 61G,OS 有CentOS 6, 7.1。主要机型是 12 核开启超线程 + 16G Mem + CentOS6,以此为调优机型
- 查看
sysctl -a系统参数是否一致,尤其是 vm.swappiness - 相同部署环境下统计 GC, 接口 SLA 是否一致
-
QPS 来源
-
tcpcopy
copy 线上流量,拦截了上行流量,在试验初期使用
-
线上灰度
完全真实场景,细粒度调优使用
以上两种来源,也决定了只能做相同时间段内的对照试验
-
-
互换实验对照
当调优参数的对性能影响的程度小于机器一致性的差异时,可做两次对照实验,第二次时将实验和对照条件互换
测量工具
没有好的测量工具不调优,错误的测量工具会导致错误的结论。看整体的平均响应以及短时间内的SLA,除非灰度的参数对性能提升明显,否则会淹没在其他因素的噪声之中(如资源sla不好,请求量不均匀),很难刻画出细粒度的性能提升。
通过看较长时间的 SLA,能够展现出细微的性能变化,推荐使用 HdrHistogram , 阅读 how not to measure latency
YGC 调优
YGC 时间占了 GC 时间的绝大部分,CMS GC只是很小的一部分,所以GC对 sla 的影响主要是
YGC导致的。YGC 调优的方向:减少 YGC 停顿时间 && 增大 YGC 间隔时间
规约条件
根据用户关系现状(如 RPC 客户端超时为100ms),人为设定每次 YGC,应用暂停不能超过 100ms。
在一次 YGC 时,Total time for which application threads = YGC stopped time + Stopping threads time (等待所有应用线程在safepoint 停止的时间),所以 YGC stopped time <= 实际中应用线程停止的时间 <= Total time for which application threads
gclog_or_tty->print_cr("Total time for which application threads "
"were stopped: %3.7f seconds, "
"Stopping threads took: %3.7f seconds",
last_safepoint_time_sec(),
_last_safepoint_sync_time_sec);
GC 日志中有:
[Times: user=0.57 sys=0.18, real=0.07 secs]
2016-01-21T11:40:43.528+0800: 76303.049: Total time for which application threads were stopped: 0.0895890 seconds
经过观察,YGC stopped time < 70ms, 能基本保证 Total time for which application threads < 100ms
为防止过早碎片化,Old 区不能太小,为了增大 YGC 间隔时间,Eden 区要越大,而物理机内存 16GB 去除堆外内存、系统和其他监控统计应用的使用内存,剩余给 JVM 堆只有12+GB,采纳双实例 5G+ 5G 的经验,将 JVM堆设为 10G,这样 14G 内存的机器也可使用。
由上得出两个规约条件
- YGC 停顿时间 < 70ms
- Eden 区 越大 且 Old 区不能太小
YGC 间隔时间
在 Eden :Old 在 1 : 1 时,较符合要求。在高峰窗口期,YGC interval 在 3s,一天的平均值在 5s。在元旦时经过实际验证,TC 机房在运行正好 6 天时,没有出现 Promotion failed 和 Full GC, YF 机房有出现 Promotion failed 。所以,Eden 区设置为了 5G
YGC 停顿时间
关于 YGC 停顿时间组成,可参考 http://blog.ragozin.info/2011/06/understanding-gc-pauses-in-jvm-hotspots.html
T (young gc) = T (scan thread stacks) + T (scan card_tables of old region to find dirty card tables) + T (from dirty card_tables to mark live set of young region) + T (copy live set of eden and survivor region to another survivor region)
可以通过减小 MaxTenuringThreashold 来减少 Survivor 区中 liveset,从而减少 copy 的时间。一个对象从在 Eden 区产生到晋升到 Old 区所需时间最小为 MaxTenuringThre shold * YGC_intervel_time, 只要增大 Eden 区,从而增大 YGC_interval_time,也就会弥补减小 MaxTenuringThreashold 带来的增多晋升到Old 区对象数的副作用。
使用+PrintTenuringDistribution在 GC 日志中查看各个 age live set 的分布。用户关系前端机短时间内 QPS 很稳定 ,Eden 区产生的 live set 也比较稳定,所以可以根据各个 age 中 live set 的变化来决定 MaxTenuringThreashold设定值,不至于让 晋升到 old 区的对象过多。如下所示 age 3 比 age2 减少的 对象并不多,所以我们决定了设置 MaxTenuringThreashold 为 3。当然准确的计算应该是追踪从 Eden 区 copy 来的对象在 Survivor 中各个 age 的减少情况,但在 QPS 和 live set较稳定下前者比较简单直观。
Desired survivor size 209715200 bytes, new threshold 3 (max 3)
- age 1: 12669496 bytes, 12669496 total
- age 2: 4045080 bytes, 16714576 total
- age 3: 3023624 bytes, 19738200 total
经 TargetSurvivorRatio 由默认值设置为 100,可以充分利用 Survivor 空间,从而为 Eden 留出更多空间。
如果使用 CMS 默认的计算值,对比结果如下

SLA 图
使用机器性能几乎一致的两台永丰机器 10.75.25.26, 10.75.25.29,以平台接口 400ms 的范围来看 SLA
前端主要各接口比例表如下:
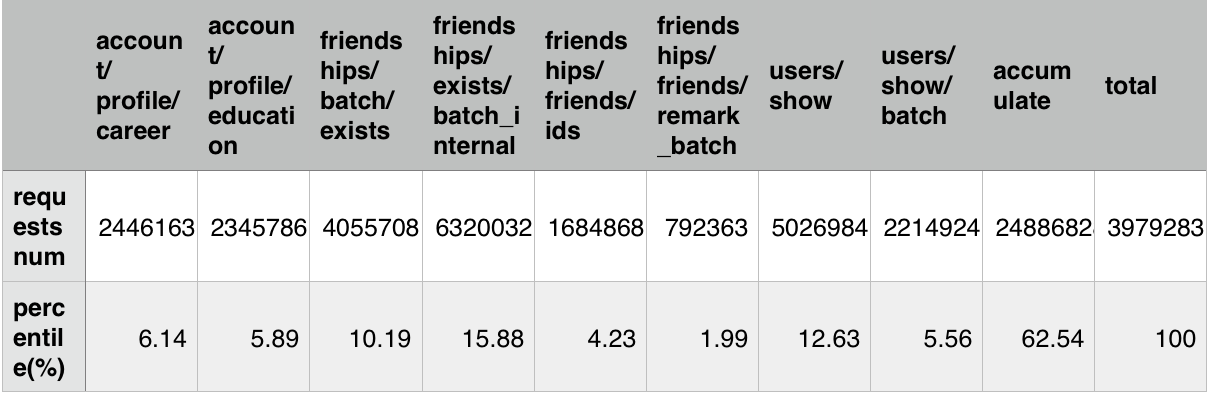
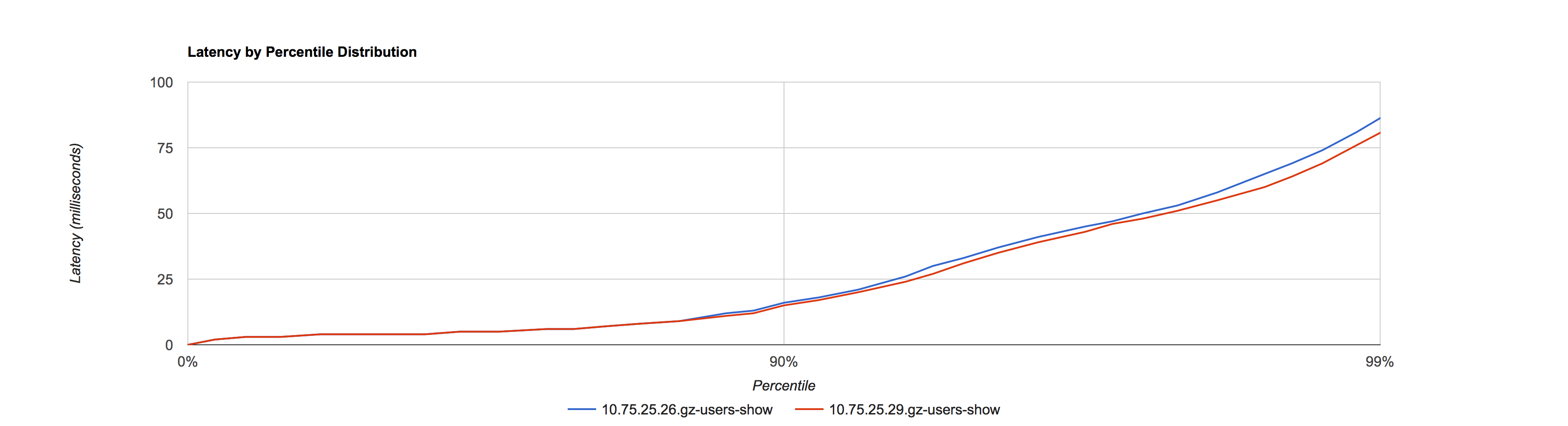
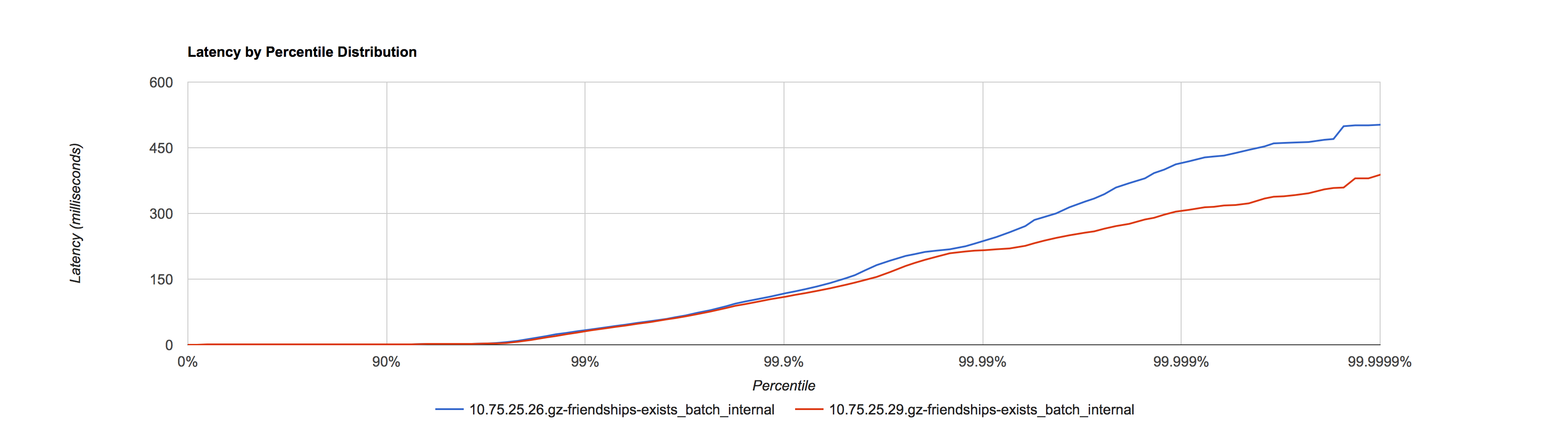
2016.01.19 晚高峰窗口 21:00 - 22:00
10.75.25.26 采用默认值作为对照,10.75.25.29调优后作为实验
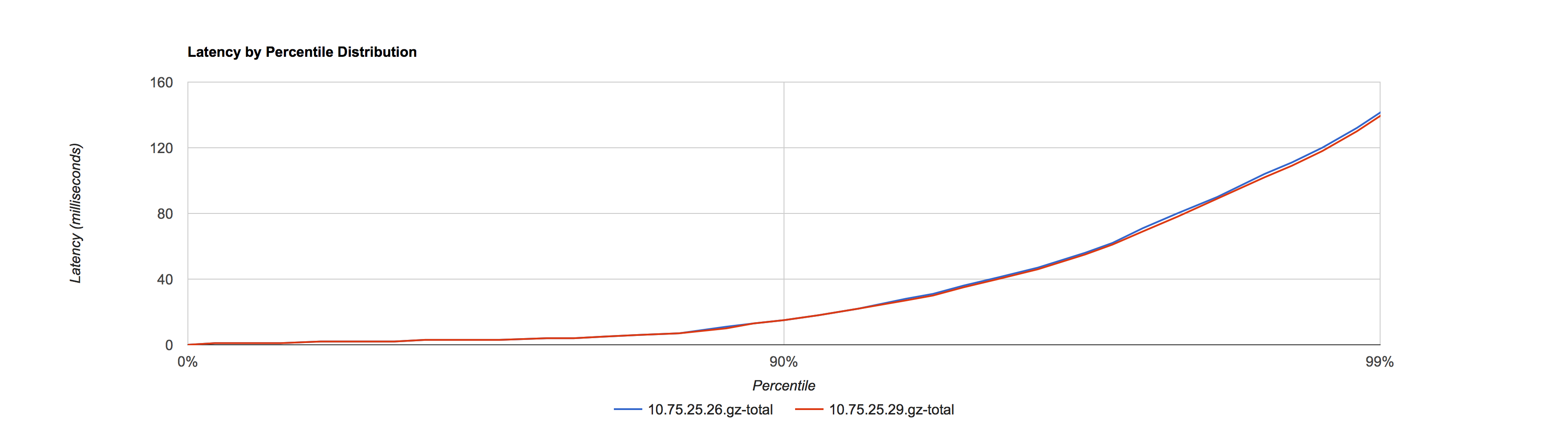
2016.01.20 晚高峰窗口 21:00 - 22:00,互换实验对照条件
10.75.25.29 采用默认值作为对照,10.75.25.26调优后作为实验
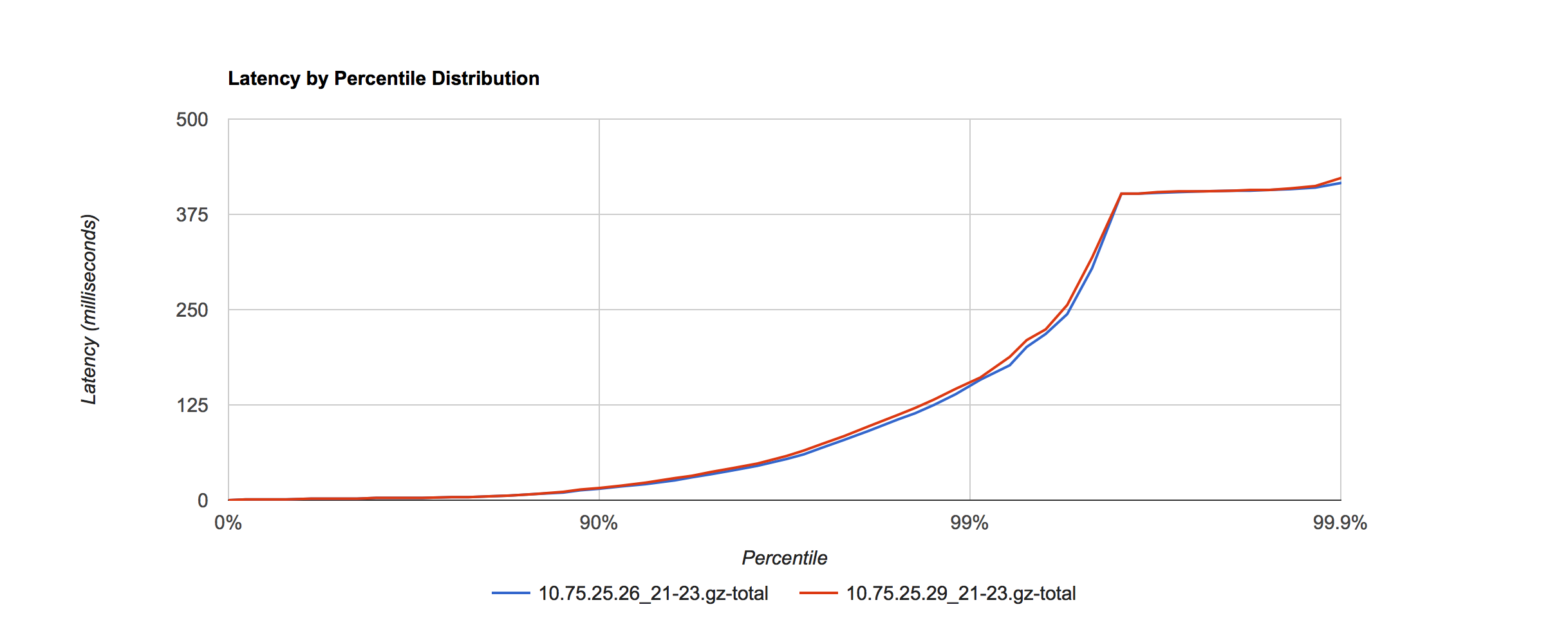
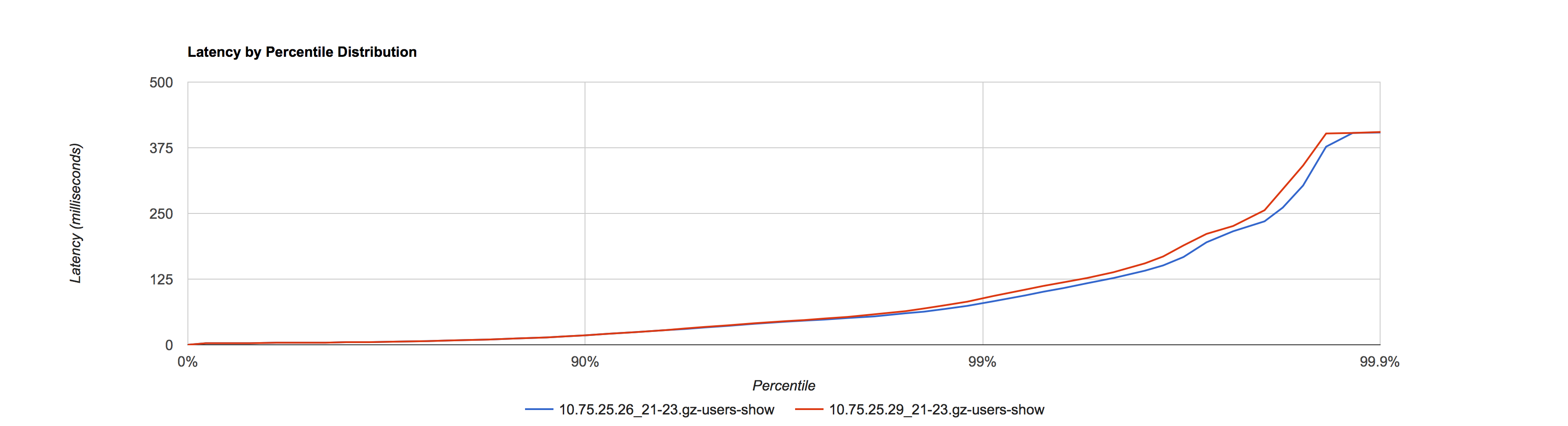
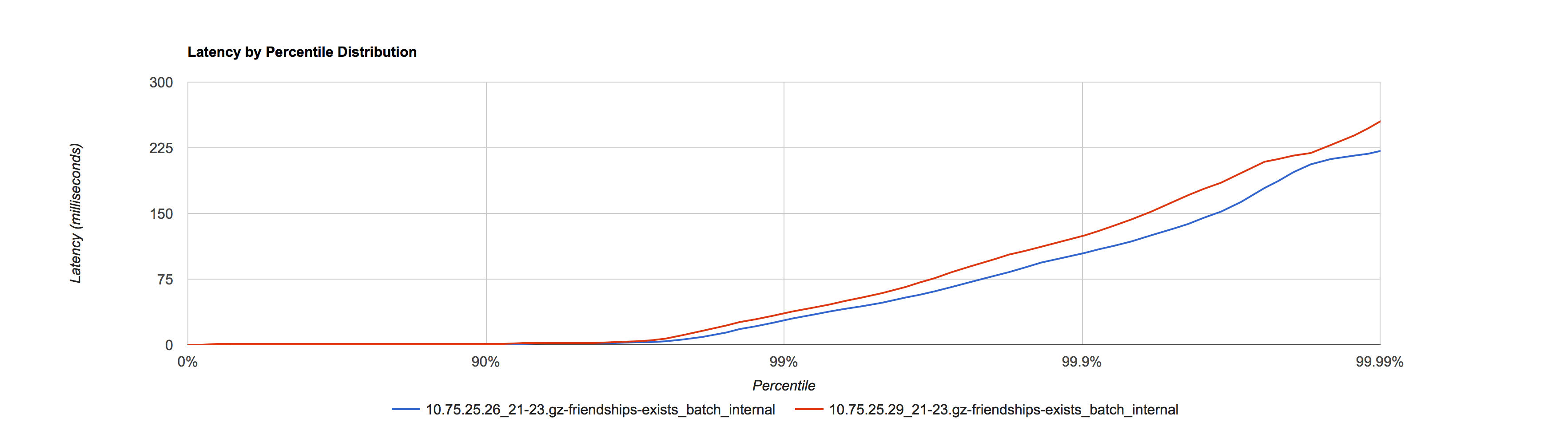
在相同的 Yong space 下,可以看出调优后参数比使用默认值对 SLA 有提升。在接口比例表中占了总结口调用量62.54% 的这8类下行接口均有提升。由于存在上行接口和一些SLA 较差的下行接口,所以导致整体的接口 SLA 区分度不大,所以在调优时可以选取众接口中 SLA 较好的接口作为测量对象,从而细化观察粒度。如果使用平均值来观察,调优前后几乎看不出区别,验证了观察工具的重要性。
CMS GC
CMS GC 7 个阶段
- intial mark
- concurrent mark
- concurrent preclean
- concurrent abortable preclean
- remark
- concurrent sweep
- concurrent reset
stop the world 阶段有两个:
- initial mark
- remark
减少 CMS 停顿就是要减少这2个阶段的停顿
intial mark
[GC [1 CMS-initial-mark: 2974272K(4956160K)] 3014023K(9932800K), 0.0186820 secs] [Times: user=0.13 sys=0.02, real=0.02 secs]
T (initial-mark stopped) = T (refs from thread stacks) + T (refs from young space),系统默认在 YGC 之后马上进行 initial-mark,所以耗时主要是 T (refs from thread stacks), 基本是一次 back-to-back 连续的停顿,由于耗时较短,所以对应用基本没有什么影响
-
CMSParallelInitialMarkEnabled
此参数在 Java7 中间版本中引入,默认 false,在 Java8 中默认 true. 并行 intial-mark,在用户关系前端机中 由 100+ms 减少到 20+ ms,但在 java8中效果没有那么显著,原因未知。阅读 [http://hiroshiyamauchi.blogspot.hk/2013/08/parallel-initial-mark-and-more-parallel.html
remark
+PrintReferenceGC 在日志中开启打印 Reference 状况
[GC[YG occupancy: 664395 K (5324800 K)]2016-01-21T12:43:23.414+0800: 78909.840: [Rescan (parallel) , 0.0454020 secs]2016-01-21T12:43:23.460+0800: 78909.886: [weak refs processing2016-01-21T12:43:23.460+0800: 78909.886: [SoftReference, 43 refs, 0.0000290 secs]2016-01-21T12:43:23.460+0800: 78909.886: [WeakReference, 2374 refs, 0.0005820 secs]2016-01-21T12:43:23.460+0800: 78909.886: [FinalReference, 16513 refs, 0.1878600 secs]2016-01-21T12:43:23.648+0800: 78910.074: [PhantomReference, 0 refs, 15 refs, 0.0000420 secs]2016-01-21T12:43:23.648+0800: 78910.074: [JNI Weak Reference, 0.0000210 secs], 0.1886290 secs]2016-01-21T12:43:23.648+0800: 78910.074: [scrub string table, 0.0078550 secs] [1 CMS-remark: 2978658K(4956160K)] 3643054K(10280960K), 0.2441570 secs] [Times: user=0.73 sys=0.24, real=0.25 secs]
从日志中看,T(remark) = T(rescan) + T(refs processing) + T(scrub string table) 。如果 Old 区小于 10G, T(scrub string table) 几乎可以忽略。
ParallelRefProcEnabled 并行 reference processing 可以显著减少 T(refs processing), 副作用是 是的 YGC stopped time 增加,在用户关系前端机上约增加了15ms。得不偿失,默认关闭,也建议关闭。参考 http://java.sun.com/j2se/1.5.0/docs/api/java/lang/ref/Reference.html
extensively, the GC work to process the Reference objects can be noticeable. It’s not necessarily worse in the low pause collector than in the other collects, but it hurts more (because we’re trying to keep the pauses low). Parallel reference processing is available for the low pause collector but is not on by default. Unless there are tons of Reference Objects, doing the reference processing serially is usually faster. Turn it on with the flag -XX:+ParallelRefProcEnabled if you make extensive use of Reference Objects (most applications don’t).
T(refs processing) 最长的时间是在 [FinalReference, 16513 refs, 0.1878600 secs],对应应用中的 finalize 方法或 finally 语句,参阅Why do finalizers have a “severe performance penalty”? 可以通过减少它们的使用来缩短此时间。感觉应该提 patch,增加开关,让 remark 开启 ParallelRefProcEnabled,而 YGC 不开启。
剩下的 T(rescan) , 可以调度 remark 在 YGC 之后马上进行,从而缩短时间。
[GC[YG occupancy: 795048 K (5324800 K)]2016-01-24T22:59:35.769+0800: 189816.558: [Rescan (parallel) , 0.0804260 secs]2016-01-24T22:59:35.850+0800: 189816.639: [weak refs processing, 0.1582360 secs]2016-01-24T22:59:36.008+0800: 189816.797: [scrub string table, 0.0107800 secs] [1 CMS-remark: 2983157K(4956160K)] 3778205K(10280960K), 0.2524220 secs] [Times: user=1.00 sys=0.31, real=0.26 secs]
如上所示,remark 在 Yong 区使用了近 800MB 时开始进行,Rescan 阶段只停顿了 80ms。如果以 YGC 停顿时间 3 s 计算,在一次约 70ms 的 YGC 后,应用运行了约(800/ 5120)* 3s = 460ms 后,又停顿了 260ms。
使用以下参数组合可以保证 remark 在 YGC 之后马上进行,不建议使用 CMSScavengeBeforeRemark,具体解释请看附
-XX:CMSScheduleRemarkEdenPenetration=1 -XX:CMSScheduleRemarkEdenSizeThreshold=1 -XX:CMSMaxAbortablePrecleanTime=50000 -XX:CMSWaitDuration=50000
CMSInitiatingOccupancyFraction
Old 区使用多少百分比时,开始进行 CMS GC,与 UseCMSInitiatingOccupancyOnly 搭配使用,表示每次触发CMS GC, old 区都是占用了此百分比,不然只表示 JVM 在启动后的第一次在此百分比进行 CMS GC,以后的 CMS GC 由 JVM 根据自己的算法来进行调度。此值的设置会跟 Old 区利用率和碎片化程度的增长相关,设置越低,Old 区利用率越低,相同次数的 CMS GC 下,碎片化增长越慢。元旦时设置为 70%, 6天运行时间 YF 出现 promotion failed, 现在用户关系前端设置为 60%
最大线程数的影响
用户关系前端机 Tomcat 使用 NIO (org.apache.coyote.http11.Http11NioProtocol) 方式。
为验证最大线程数对 SLA 的影响,将机器 10.73.32.25 - 28, 分别设置线程数为 100, 200, 600, 1000
YGC 效果没有多大分别,SLA 如下:
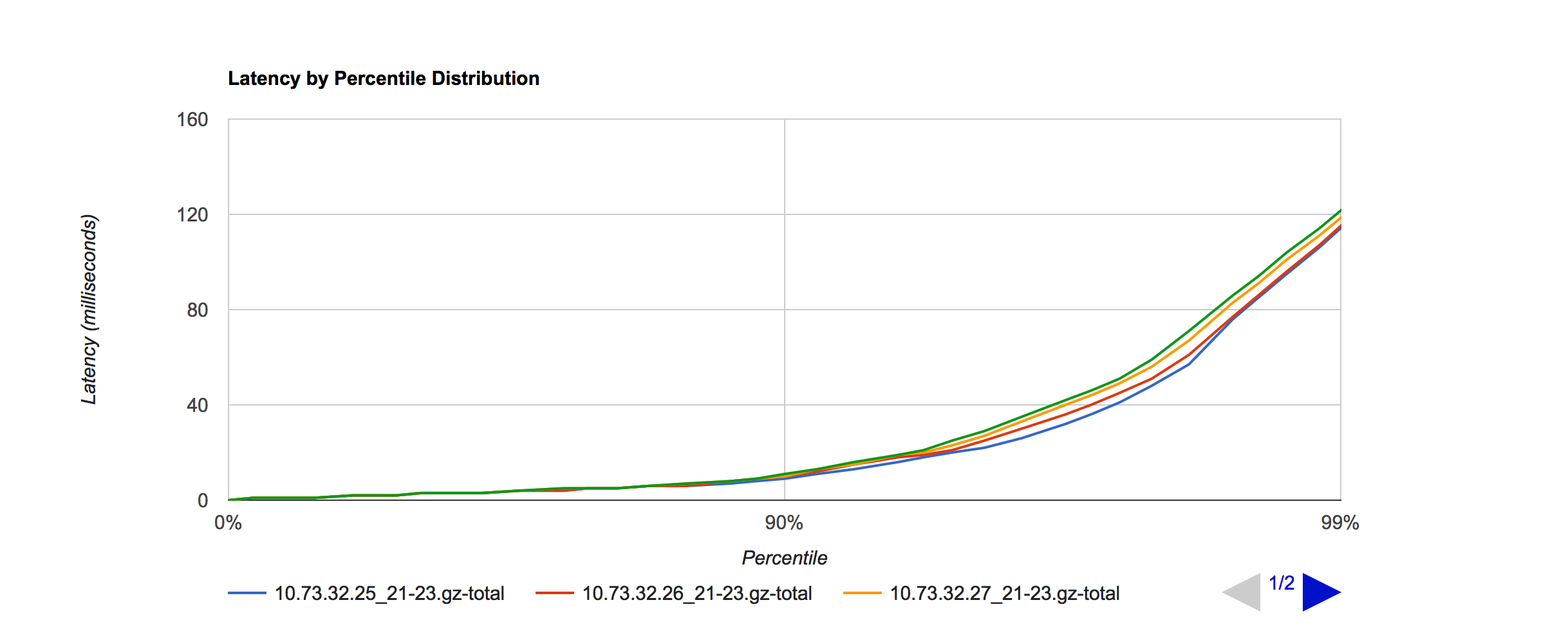
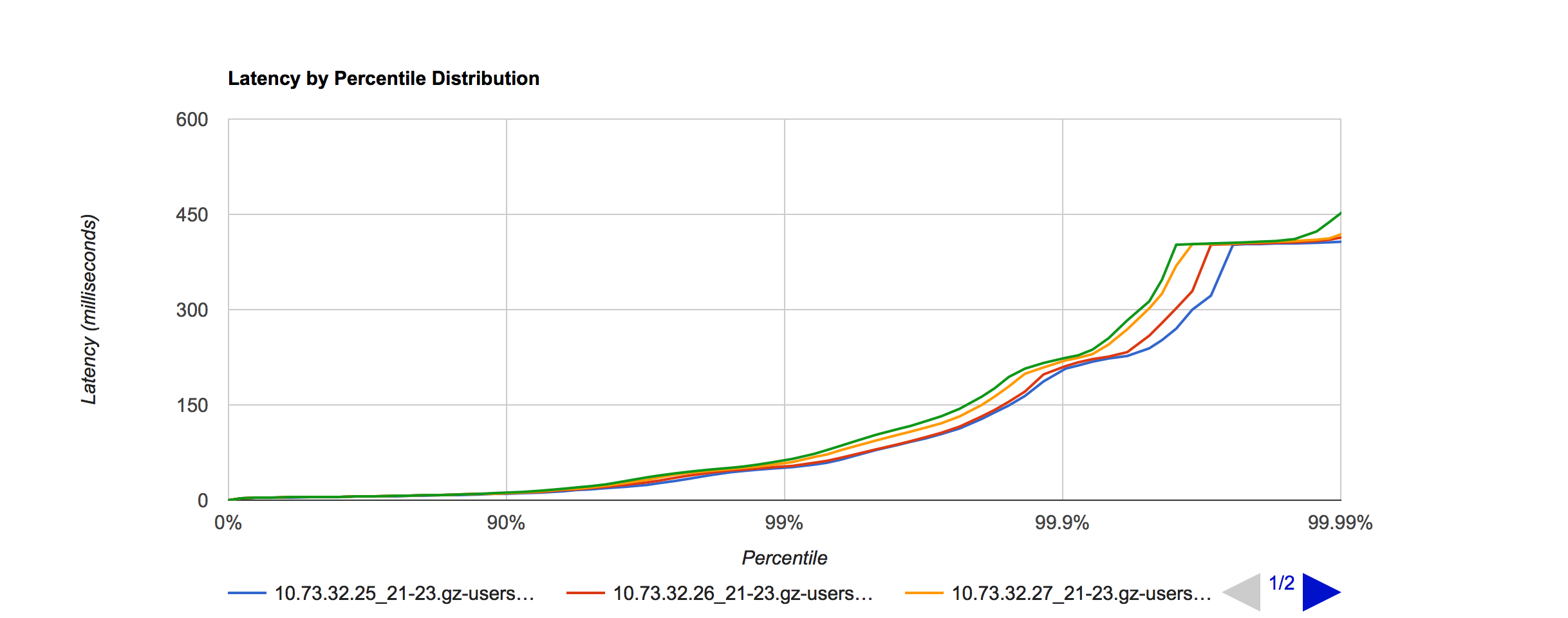
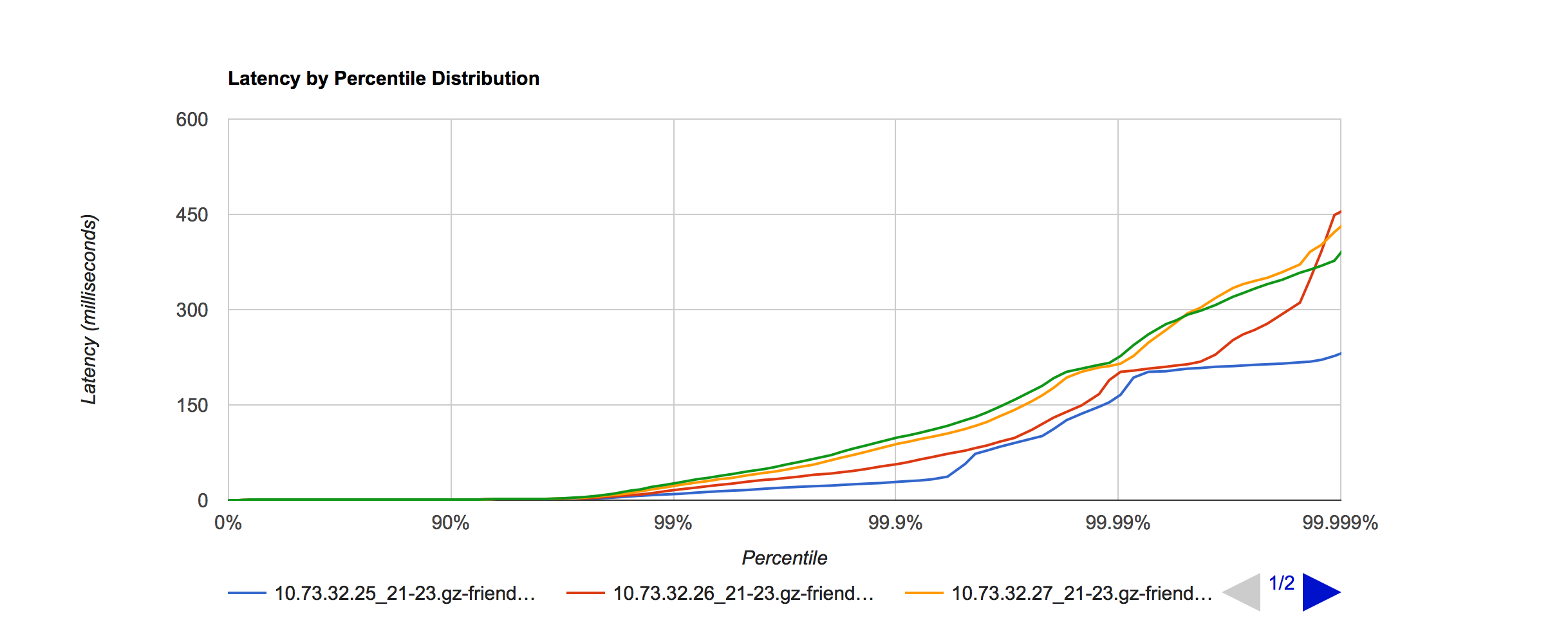
呈现出线程数越少,SLA 越好。线程数 对 SLA 的影响还是比较明显的
JIT 的影响
ReservedCodeCacheSize=256m, 默认 48MB(64-bit JVM), 设置较大,可防止因占满而停止 JIT
当时 用户关系前端机 单实例 全量后,YF 机房在运行一天后,出现接口性能下降。当时 TC 机房没有出现,以为是代码原因,后面飞哥,令书解决此问题。
今后方向
Java8 + Tomcat8
通过对比许多参数,发现调优后的不少参数都已经在 Java8 (Java8u66)中设置了, 所以升级版本,使用系统默认参数,是 GC调优的最直接方式。
其他可调参数
- TieredCompilation 开启多层编译,初始 -client, 之后 -server, 吸取两者所长
- AutoBoxCacheMax=100000 设置
new Integer(100)之类自动装箱缓存上限由 127 到 100_000 - AlwaysPreTouch,在 JVM 启动时, touch 到 -Xms 指定大小物理内存,从而避免之后的虚拟内存页到物理内存页的 page fault,线上已在用
- UseBiasedLocking 取消使用偏向锁,具体性能未验证
- UseLargePages, 设置较大会较少 TLB miss,需要 Linux 支持,我们现在系统默认 2 MB
- UseNUMA,开启 NUMA 模式,减少缓存失效,具体效果还需细粒度观察
- 逃逸分析 DoEscapeAnalysis PrintEscapeAnalysis
- 标量替换 EliminateAllocations PrintEliminateAllocations
- 同步消除 EliminateLocks
统计参数
-
-DisableExplicitGC, 不关闭 system.gc()
-
+ExplicitGCInvokesConcurrent, 使 system.gc() 使用 CMS gc
-
-CMSClassUnloadingEnabled, CMS gc 时 不回收 Perm 区,缩短 remark 停顿时间
-
+PrintPromotionFailure,出现 Promotion failed 时,打印原因
-
PrintFLSStatistics=2, 打印 Old 区内存碎片化状况
-
+PrintReferenceGC, 打印处理 Reference 状况
附
如果有兴趣阅读 Hotspot CMS 源码,可以参考http://jangzq.info/2015/08/29/cms/
CMS源码框架
switch (_collectorState) {
case InitialMarking:
{
VM_CMS_Initial_Mark initial_mark_op(this);
VMThread::execute(&initial_mark_op);
// call checkpoingRootsIntial(async)
}
break;
case Marking:
markFromRoots(true)
break;
case Precleaning:
preclean();
case AbortablePreclean:
abortable_preclean();
break;
case FinalMarking:
{
VM_CMS_Final_Remark final_remark_op(this);
VMThread::execute(&final_remark_op);
// call checkpointRootsFinal(async, !clear_all_soft_refs,
!init_mark_was_synchrous)
}
break;
case Sweeping:
sweep(true);
case Resizing: {
...
break;
}
case Resetting:
reset(true);
break;
case Idling:
default:
ShouldNotReachHere();
break;
}
// concurrentMarkSweepGeneration.cpp#CMSCollector::checkpointRootsFinal
if (CMSScavengeBeforeRemark) {
gch->do_collection(true, // full (i.e. force, see below)
false, // !clear_all_soft_refs
0, // size
false, // is_tlab
level // max_level
);
}
CMSScavengeBeforeRemark, 在 Remark 时额外触发 YGC, 而不是等到 YGC 时再调度 Remark, 所以会额外增加 1 次 YGC, 并且当此策略失败时,停顿也较长,不建议使用
preclean() 阶段
if (get_eden_used() < (capacity/(CMSScheduleRemarkSamplingRatio * 100)
* CMSScheduleRemarkEdenPenetration)) {
_start_sampling = true;
}
CMSScheduleRemarkEdenPenetration (默认50%), 此值越小,对 Eden 区采样越早
abortable_preclean() 执行 preclean() 并寻找时机 break
if (pa.wallclock_millis() > CMSMaxAbortablePrecleanTime) {
if (PrintGCDetails) {
gclog_or_tty->print(" CMS: abort preclean due to time ");
}
break;
}
设置 CMSMaxAbortablePrecleanTime(默认 5_000)较大,可防止因超时而 break, 产生 "CMS: abort preclean due to time"
if (get_eden_used() > CMSScheduleRemarkEdenSizeThreshold)
// If Eden's current occupancy is below this threshold, immediately schedule the remark
CMSScheduleRemarkEdenSizeThreshold (默认 2 M), 当 Eden 区的使用大于此值时,并进行 Remark 的调度,如果此值较小,并且 CMSScheduleRemarkEdenPenetration 较小,则 Remark 会在 1次 YGC 之后几乎马上调度 Remark, 从而使大大缩短 Remark 阶段 Rescan 所停顿的时间
void ConcurrentMarkSweepThread::sleepBeforeNextCycle() 中:
if(CMSWaitDuration >= 0) {
// Wait until the next synchronous GC, a concurrent full gc
// request or a timeout, whichever is earlier.
wait_on_cms_lock_for_scavenge(CMSWaitDuration);
} else {
// Wait until any cms_lock event or check interval not to call shouldConcurrentCollect permanently
wait_on_cms_lock(CMSCheckInterval);
}
CMSWaitDuration(默认 2_000), 设置较大会 留给 CMS GC 足够的时间进行 abortable_preclean() 阶段