Gunicorn aiohttp PyTorch 高并发打分服务
介绍下自己实现的一个在线 Pytorch inference 框架, 代码在 https://github.com/itsliupeng/online_http_pytorch
训练完模型后,部署模型使用 HTTP 协议还是比较方便的。大多数深度学习训练框架都是支持 Python,所以部署时选用 Python 的框架,可以实现从模型训练到部署在同一套语言体系下,非常方便。
传统的 HTTP flask 框架,多进程方式部署,直观简单。但是由于 GPU 卡的内存是有限的,所以一个 GPU 卡最好部署少于 MAX_PROCESSES_PER_GPU 个进程, 这些进程所占显存不超过最大显存数,不然多一个进程就要多占用一份模型大小的显卡内存。所以进程数限制为 GPU 卡数 * MAX_PROCESSES_PER_GPU,由于进程数有限制。所以不能并发很多 flask 进程,从而限制了整体系统的并发。
我使用的 GPU 机器单机 4 卡,可以用 Gunicorn 起 4 * MAX_PROCESSES_PER_GPU 个进程,MAX_PROCESSES_PER_GPU 个进程独占一个 GPU 卡。
在一个进程中如何提高并发,python 3.5 版本之后标准库支持携程 coroutine, asyncio,原语 asycn await 等也比较直观,使用 aiohttp 可以很方便实现 http 服务。
如何实现进程独占绑定 GPU
在 gpu_stat module 中通过 py3nvml 可获取当前 GPU 的 id 和上面运行的进程 pid
use_gpu = len(gpu_stat.get_available_gpu_ids()) > 0
def get_gpu_id():
if use_gpu:
current_pid = os.getpid()
print('current_pid: ' + str(current_pid))
sibling_pid_time = sorted(map(lambda x: (x.pid, x.create_time()), psutil.Process(current_pid).parent().children()), key=lambda x: x[1])
print('sibling_pid_time: ' + str(sibling_pid_time))
sibling_pids = map(lambda x: x[0], sibling_pid_time)
for pid in sibling_pids:
if pid == current_pid:
return gpu_stat.get_available_gpu_ids(MAX_PROCESSES_PER_GPU)[-1]
bind_gpu = False
for gpu_id, pids in gpu_stat.get_pids().items():
if pid in pids:
bind_gpu = True
if not bind_gpu:
print('waiting pid %s to bind gpu' % str(pid))
time.sleep(3)
return get_gpu_id()
else:
return ''
比如 Gunicorn 启动 4 个 worker 进程,可以根据当前进程获取到 sibling 同伴进程的 id 和启动时间,根据启动时间先后排序后,优先让启动时间早的同伴进程去后去空闲 GPU,等到比自己启动时间早的同伴进程都已绑定进程后自己再获取空余 GPU 卡,加载模型,从而占用该 GPU 卡。如此实现了一个进程去独占绑定一个 GPU 卡。
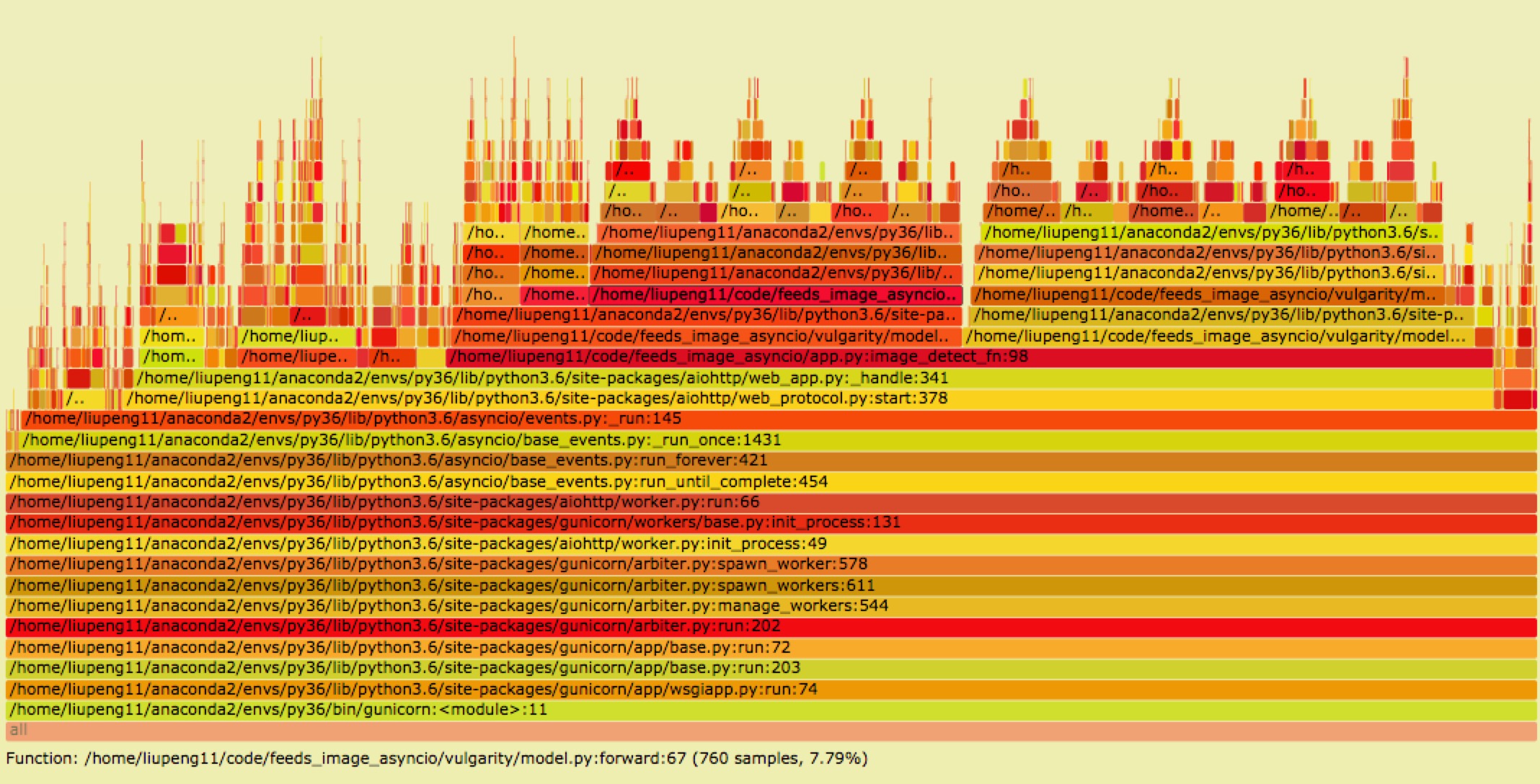
pyflame
python 的火焰图可以使用 pyflame
install conda install -c eklitzke pyflame
usage pyflame -s 10 -r 0.01 -p <pid> | flamegraph.pl > 0.svg