PyTorch NvJPEG 加速图像解码预处理
背景
目前大多数图像和视频推理服务的输入都以 JPEG 作为图像格式,JPEG 图像压缩算法比较复杂,相对的 JPEG 解码也需要比较多的计算资源,另外图像预处理也是计算密集型的操作,需要大量计算资源。
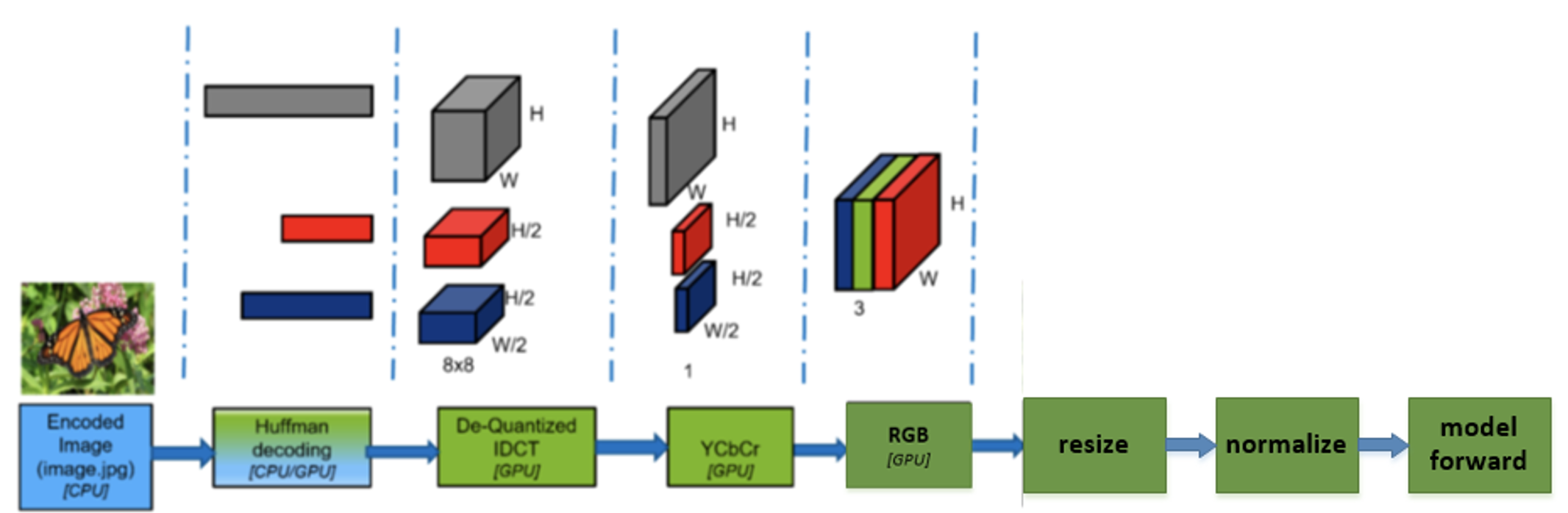
在线推理服务中, CPU 算力相对 GPU 算力不是那么充足(比如单机8卡的机型,一般是 80 个超线程 CPU 核 + 8 张 GPU 卡,每张 GPU 只能分配 10 个 CPU 核,也就是 1 张 GPU 卡平均分配到不超过 10 个 CPU 超线程核)。在 CPU 上解码和预处理 + GPU 模型前向计算的推理链路中,CPU 使用率远大于 GPU 使用率,整个链路瓶颈在于 CPU 的算力不足,导致单独只做模型前向计算,即模型预测的优化,在整个推理链路中收益不明显。将解码和预处理从 CPU 移到 GPU 上操作将极大提升整个推理链路的性能。
使用 GPU 解码 JPEG 图像
Nvidia 在 Cuda 库中有一个 nvJPEG lib 包 , The NVIDIA Data Loading Library (DALI) 基于此实现了训练侧使用 GPU 解码图像。
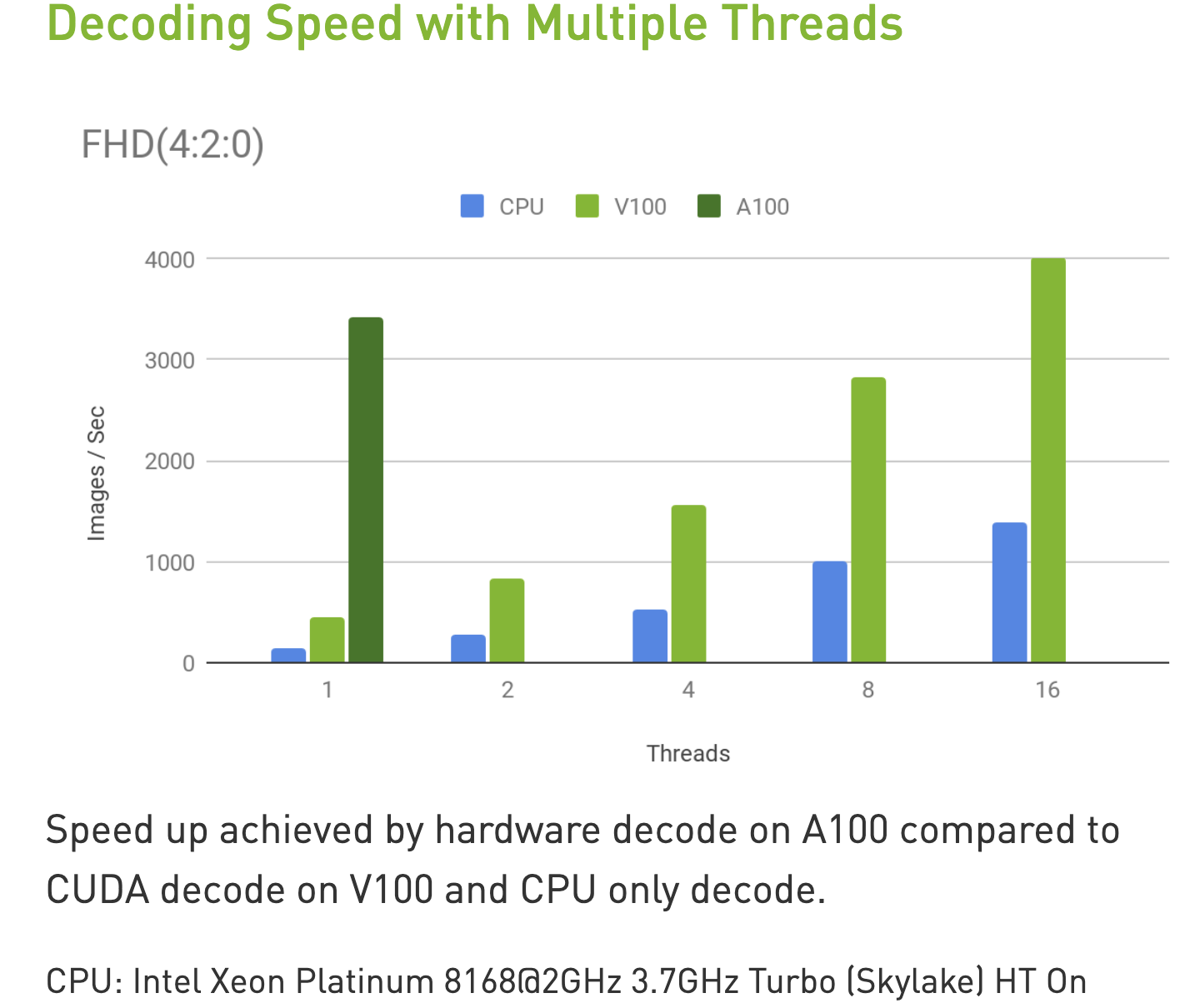
基于 NvJPEG 官方的解码性能图,我们可以得出 GPU 解码相对于 CPU 解码有约 2.5 倍的加速比(实际业务中,CPU 还会有其他负载,比如预处理,rpc 序列和反序列化等,加速比会更大)。
diff 问题
我们测试发现,不同的 JPEG 解码库,包括 libjpeg, libjepg-turbo, nvJPEG 对同一张 JPEG 图像解码后存在着 diff,并不完全一致,另外图像 resize 等预处理操作不同的库实现方式也不完全一致。
同一张 JPEG 图像,存在着 diff 的不同的解码和预处理,导致模型输入不同,最终结果也不同。所以有必要统一训练和预测的解码和预处理逻辑,保持完全一致。
DALI 使用了 nvJPEG 解码和 NPP(NVIDIA PERFORMANCE PRIMITIVES) 图像预处理, 业务模型大多是 PyTorch 版本, 需要我们需要去兼容已在使用的 torchvison transforms的操作。另外 DALI 使用起来并不灵活方便,debug 比较困难。
所以我们开发了可以在 PyTorch 中使用 nvJPEG + torchvision transforms 作图像预处理的比较灵活方便方案。
torchnvjpeg
通过 libtorch+nvjpeg 实现了解码图像为 torch Tensor,可直接用于 torchvision transforms 作图像预处理,通过 pybind11 提供了 Python 接口,源码地址
安装方式为 pip install torchnvjpeg-0.1.0-cp36-cp36m-linux_x86_64.whl
import torch
import torchnvjpeg
decoder = torchnvjpeg.Decoder()
# 读取图像字节流
image_data = open("images/cat.jpg", 'rb').read()
# 使用 nvjpeg 解码
image_tensor = decoder.decode(image_data) # run on GPU
assert image_tensor.is_cuda
# 使用 torchvision.transform 的图像预处理算子
import torchvision
transform = torchvision.transform.Resize((224, 224))
resized_tensor = transform(image_tensor.permute((2, 0, 1))) # run on GPU
同时支持 batch decode 和 多线程 parallel decode,多线程安全。实际使用中,建议使用 parrallel decode, 示例如下
import torch
import torchnvjpeg
from multiprocessing.pool import ThreadPool
batch_size = 8
image_path = "images/cat.jpg"
data = open(image_path, 'rb').read()
data_list = [data for _ in range(batch_size)]
decoder_list = [torchnvjpeg.Decoder() for _ in range(batch_size)]
cpu_threads = 8
pool = ThreadPool(cpu_threads)
def run(args):
decoder, data = args
return decoder.decode(data)
image_tensor_list = pool.map(run, zip(decoder_list, data_list))
另外支持传入不同的 cuda stream 和设置 max_cpu_threads, max_image_size 等参数,具体查看 torchnvjpeg.Decoder 说明
In [5]: ? torchnvjpeg.Decoder
Init docstring:
__init__(*args, **kwargs)
Overloaded function.
1. __init__(self: torchnvjpeg.Decoder, device_padding: int = 0, host_padding: int = 0, gpu_huffman: bool = True, device_id: int = 0, max_image_size: int = 24883200, stream: object = None) -> None
Initialize nvjpeg decoder.
Parameters:
device_padding: int, set 0 by default
host_padding: int, set 0 by default
gpu_huffman: bool, whether to use GPU for Huffman decode, set true by default
device_id: int, gpu id, set 0 by default
max_image_size: int, maximum image size (h * w * c) to decode, set 3840*2160*3 by default
stream: torch.cuda.Stream, if None, using torch.cuda.current_strea
benchmark
测试环境:
- 通过 python grpc 部署服务, 服务实例为 8 CPU 超线程核 + 1 T4 16G GPU, 服务端开启 8 个 worker
- 模型 resnet50 单帧模型,使用 TRTorch float 16 加速,batch_size 8
- 不包含使用 CPU 的后处理,除去无关的 CPU 消耗
- 测试图像选用 imagenet 训练集 n03141823,平均 size 在 500 * 411
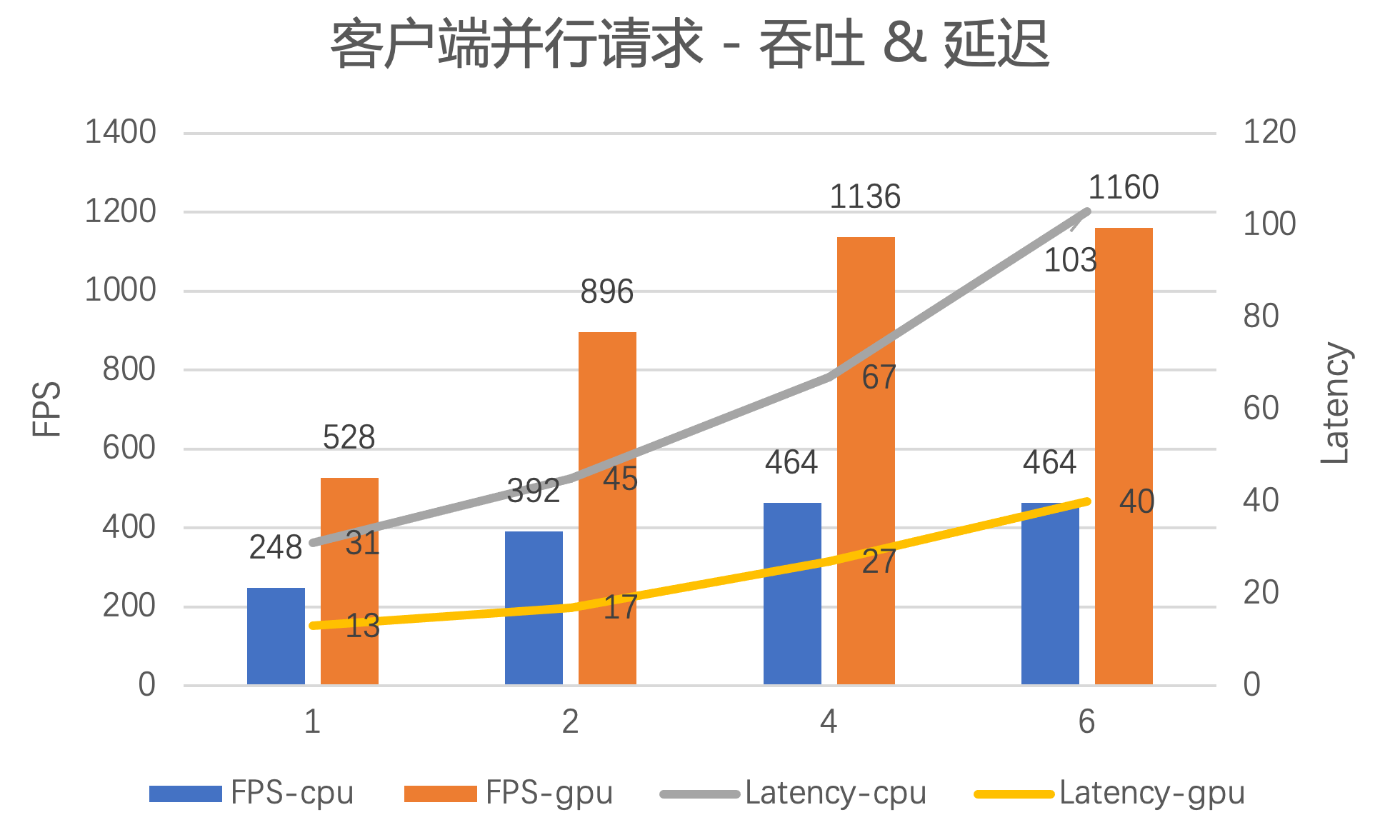
可以看到:
- 峰值 FPS 提升至 1160 / 464 = 2.5 倍, 1 个服务实例 1 天最多可处理 1160 * 3600 * 24 ~= 1 亿张图 / 天
- 峰值时延迟下降至 27 / 67 ~= 40%
- 支持更多的客户端并行调用
另外,把 CPU 核数从 8 增加至 16 ,性能压测结果如下
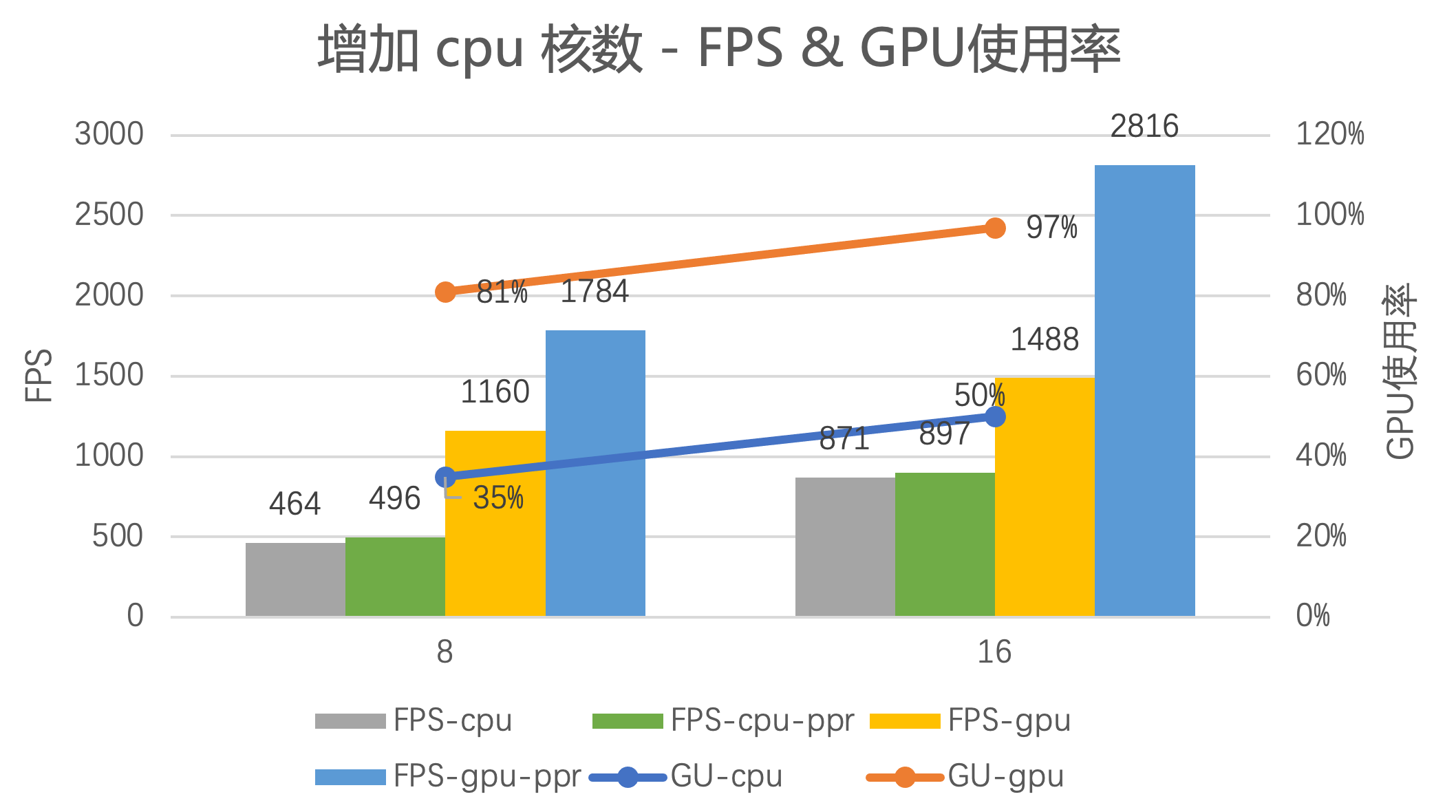
- CPU 核数在 8 或 16 时,灰色柱状图 FPS-cpu (cpu 解码预处理+模型预测) 与绿色柱状图 FPS-cpu-ppr(只有 cpu 解码预处理,不包含模型预测) 结果都很接近,说明整个推理链路瓶颈在于解码预处理部分,而不是模型推理。此时的 CPU 使用率都已在 100%
- 增加 CPU 核数从 8 到 16, 都可以进一步提升性能: CPU 解码和预处理+模型前向的 GPU 使用率 35% -> 50%; GPU 解码和预处理+模型前向的 GPU 使用率 81% -> 97% ,已到极限。
- 蓝色柱状图 FPS-gpu-ppr 是只做 GPU 解码和预处理,不做模型预测,表示整个解码预处理的性能极限,远大于 黄色柱状图 FPS-gpu (包含模型预测的),说明服务的瓶颈在于模型预测
- 另外,Resnet50 fp16 单独模型预测(不包含解码预处理,输入已经在 gpu 上)的 FPS 为1630,cpu 核数为 16 时,服务FPS 为 1488,1488 / 1630 = 91.2% ,可以得出解码和预处理消耗的 GPU 资源占比很少
我们在压测中还发现:
- 图像尺寸越大,GPU 解码和预处理的优势越大
- 对于输入为多帧的服务,GPU 解码和预处理的的优势越大
- 供解码和预处理的 CPU 核数越少,进一步拉低 CPU 解码和与处理的性能,比如 CPU 核数设置为 4 或后处理操作使用 CPU
训练中使用 torchnvjpeg
之前我们发现不同版本的解码和预处理的实现之间都存在 diff 问题,虽然人眼很难分辨,但是对于输入很敏感的模型(比如过拟合的模型),会有预测结果的 diff。可以在训练中也是用 torchnvjpeg + torchvison.transforms, 保证训练和部署服务的解码和预处理版本完全一致,则不存在模型输入的 diff 问题
为了尽量更少地侵入性修改已有的训练 data_loader 代码,可以使用 gpu_loader https://github.com/itsliupeng/torchnvjpeg/blob/main/py/train/gpu_preprocess.py#L44 代理原有的 data_loader
在 gpu_preprocess.py 中提供了以下帮助方法来修改训练代码中的原有data_loader
def read_image_bytes(image_path: str):
return open(image_path, 'rb').read()
def identity_collate(batch):
return batch
def pop_decode_and_to_tensor(t: torchvision.transforms.Compose):
if not torch.distributed.is_initialized() or torch.distributed.get_rank() == 0:
print('*** Remove useless transform ***')
print('Before filter:')
print(t)
filtered_t = []
for x in t.transforms:
if isinstance(x, torchvision.transforms.Normalize) or isinstance(x, torchvision.transforms.ToTensor):
continue
filtered_t.append(x)
new_t = copy.deepcopy(t)
new_t.transforms = filtered_t
if not torch.distributed.is_initialized() or torch.distributed.get_rank() == 0:
print('After filter:')
print(new_t)
return new_t
- 将原有的 data_loader 中 读取 image 的方法替换为 read_image_bytes, 即不作图像字节流到 RGB 图像的转换
- torch.utils.data.DataLoader 的参数 collate_fn 设置为 identity_collate, 即不做 batch 的组合
- 以上 2 处的操作交由 gpu_loader 操作,使用 data_loader = gpu_loader(data_loader, pop_decode_and_to_tensor(train_transform))
总结
我们提供了一套 torchnvjpeg + torchvision.transforms 的使用 GPU 作解码预处理的方案
- 接口简单,易用性好
- 高性能,解决了推理链路中解码和预处理的瓶颈问题
- 并提供解决训练和预测因为解码和预处理不同带来的 diff 问题的方案
- 已在多个业务服务中使用部署,获得至少减少一半资源使用,并降低一半服务延迟的收益